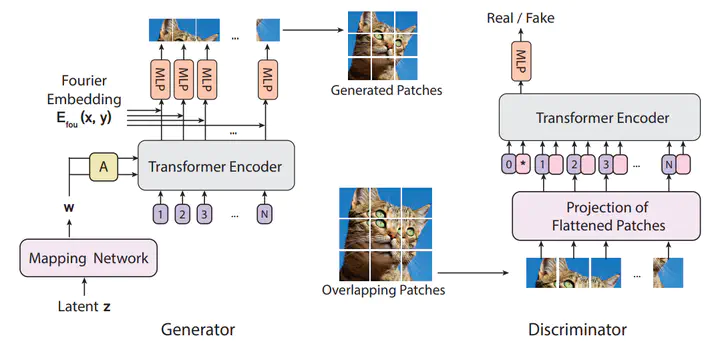
 Architecture
Architecture
A modular Pytorch Implementation of ViTGAN based on https://arxiv.org/abs/2107.04589v1
The goal of this projet is to provide a comprehensive framework to experiment with the ViTGAN architechture.
Getting Started
The main file on the provided code contains a simple example using MNIST, which can be trained relatively quickly. All hyper parameters of the model are specified in the .json files. More details are posted on the project link.
Contributors
Lise Le Boudec, Nicolas Olivain, Paul Liautaud
Key References
[1] ViTGAN: Training GANs with Vision Transformers, Kwonjoon Lee, Huiwen Chang, Lu Jiang, Han Zhang, Zhuowen Tu, Ce Liu. Jul-2021
[2] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby Oct-2020
[3] The Lipschitz Constant of Self-Attention, Hyunjik Kim, George Papamakarios, Andriy Mnih Jun-2020
[4] Attention Is All You Need, Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin Jun-2017
[5] Generative Adversarial Networks, Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio Jun-2014
See also
One can check this repository for a more minimalistic implementation.
Help us with a on our repository.