import mathimport timeimport osimport pickleimport numpy as np import scipy.stats as sps import matplotlib.pyplot as pltimport seaborn as sns sns.set_theme()import pandas as pdfrom tqdm import tqdmfrom numpy.random import default_rng, SeedSequencesq = SeedSequence()seed = sq.entropy # on sauve la graine pour reproduire les résultatsrng = default_rng(sq)
2.1 Retour sur Monte Carlo avec erreur préscrite
Pour un échantillon \((X_i)_{1 \leq i \leq n}\) de taille \(n\) l’estimateur Monte Carlo se contruit à partir de l’estimation de la moyenne empirique \(\hat m_n\) et de l’estimation de la variance empirique \(\hat \sigma^2_n\) définies par \[
\hat m_n = \frac{1}{n} \sum_{i=1}^n X_i \quad \text{et} \quad
\hat \sigma_n^2 = \frac{n}{n-1} \big( \frac{1}{n} \sum_{i=1}^n X_i^2 - \hat m_n^2 \big)
\] La taille de l’intervalle de confiance de niveau \(\alpha\)
Code de la fonction monte_carlo_adaptive
def monte_carlo_adaptive(sampling_function, epsilon: float, batch_size: int=100000, proba: float=0.95) ->dict:""" Effectue une estimation Monte Carlo adaptative jusqu'à ce que l'intervalle de confiance de la moyenne soit inférieur à epsilon. Args: - sampling_function (callable): Une fonction qui produit des échantillons de taille donnée en argument. - epsilon (float): La taille maximum tolérée pour l'IC. - proba (float): Niveau de confiance pour l'intervalle (défaut: 0.95). - batch_size (int): Taille du batch pour les simulations. Returns: - dict: Un dictionnaire contenant les valeurs suivantes : - "mean" (float): Moyenne de l'échantillon final. - "var" (float): Variance de l'échantillon final. - "ci_size" (float): Taille de l'intervalle de confiance. - "samples_size" (int): Nombre de tirages effectués. - "time (s)" (float): Temps d'execution en secondes. """ alpha =1- proba quantile = sps.norm.ppf(1- alpha /2) sum_, sum2_, size_ =0, 0, 0 start = time.time()with tqdm(total=None, desc="Adaptive Monte Carlo") as pbar:whileTrue:# Génération d'un nouveau batch d'échantillons samples = sampling_function(batch_size) sum_ += samples.sum().item() sum2_ += (samples**2).sum().item() size_ += batch_size mean = sum_ / size_ var = size_ / (size_-1) * (sum2_ / size_ - mean**2) ci_size =2* quantile * math.sqrt(var / size_)# Mise à jour de tqdm avec la taille de l'IC actuelle pbar.set_postfix({"IC_size": ci_size, "mean": mean, "var": var}) pbar.update(batch_size)if ci_size <= epsilon:break stop = time.time()return {"mean": mean,"var": var,"ci_size": ci_size,"samples_size": size_,"time (s)": stop-start, }
2.2 Options basket: pricing Monte Carlo
Dans cette première partie on na fait pas de la programmation orientée objet mais on s’en approche en rassemblant tous les paramètres dans un dictionnaire.
Note
Il est conseillé d’éviter les variables globales (pour prendre de bonnes habitudes de programmation et réutiliser facilement son code), donc on va regrouper les différents paramètre dans un dictionnaire.
def model_bs(d, r, S0, sigma, correlation, T):""" Initialise les paramètres du modèle multidimensionnel de Black-Scholes. Args: - d (int): Dimension, représentant le nombre d'actifs dans le panier. - r (float): Taux d'intérêt sans risque. - S0 (np.ndarray): Vecteur des prix initiaux des actifs, de taille (d,). - sigma (np.ndarray): Vecteur des volatilités des actifs, de taille (d,). - correlation (np.ndarray): Matrice de corrélation, de taille (d, d). - T (float): Maturité de l'option (temps jusqu'à l'échéance). Returns: - dict: Un dictionnaire contenant les paramètres du modèle. """return {"d": d,"r": r,"S0": S0,"sigma": sigma,"mu": r -0.5* sigma**2,"correlation": correlation,"correlation_cholesky": np.linalg.cholesky(correlation),"T": T,"actualization": math.exp(-r * T) }d =40rho =0.3bs = model_bs(d=d, r=0.1, S0=np.full((d), 100), sigma=np.full((d), 0.3), correlation=np.full((d,d), rho) + (1-rho)*np.eye(d), T=1)
2.2.1 Code numpy
On considère \(d \ge 2\) actifs financiers dont la loi à l’instant \(T > 0\) est modélisée par une loi log-normale c’est à dire \[
\forall i \in \{1,\dots,d\}, \quad
S^i_T = S^i_0 \exp\Bigl( \bigl(r-\frac{\sigma_i^2}{2}\bigr) T + \sigma_i \sqrt{T} \tilde G_i \Bigr)
\] où le vecteur \((\tilde G_1,\dots, \tilde G_d)\) est gaussien centré de matrice de covariance \(\Sigma\) et les constantes \(r > 0\), \(\sigma_i > 0\) sont fixées. Il s’agit d’actifs financiers \((S^i_t)_{t \in [0,T]}\), \(1 \le i \le d\), modélisés par un processus de Black-Scholes multidimensionnel. On introduit la matrice \(L\) triangulaire inférieure obtenue par la décomposition de Cholesky de la matrice \(\Sigma = L L^\top\).
A l’aide de cette matrice \(L\), on définit la fonction \(\Phi:\mathbf{R}^d \to \mathbf{R}^d\) telle que \[
(S^1_T, \dots, S^d_T) = \Phi(G_1, \dots, G_d) \quad \text{ou encore} \quad S^i_T = \Phi_i(G_1, \dots, G_d)
\] où \((G_1, \dots, G_d) \sim \mathcal{N}(0, I_d)\) (l’égalité précédente est à considérer en loi).
La fonction phi correspond au modèle financier choisi (ici Black-Scholes) et doit être modifié si on change de modèle. Il est utile d’écrire cette fonction comme transformation d’un vecteur \((G_n)_{n=1,\dots,d}\) pour faciliter l’implémentation des méthodes de réduction de variance.
La fonction suivante sampling_payoffs regroupe
la simulation du vecteur \((G_n)_{n=1,\dots,d}\) (en fait un nombre size de vecteurs de \(\mathbf{R}^d\))
l’application du modèle via l’appel de phi
la transformation via la fonction payoff \(g:\mathbf{R}^d \to \mathbf{R}\)\[
g(S_T) = \Bigl( \frac{1}{d} \sum_{i=1}^d S^i_T - K \Big)_+
\]
On regroupe dans une fonction run l’appel de la fonction monte_carlo_adaptive pour différentes valeurs de \(K \in \{80,90,100,110,120\}\). La fonction prend comme argument la fonction sampling_payoffs (et ses arguments) car c’est la fonction qui sera modifiée dans la suite.
Code de la fonction run utilisé dans toute la séance
def run(name, function, epsilon, batch_size, **kwargs): filename ="02_data/"+ name +".pkl"if os.path.exists(filename): withopen(filename, "rb") asfile: result_df = pickle.load(file)else: result = {} for K in [80, 90, 100, 110, 120]: result[K] = monte_carlo_adaptive(lambda size: function(K, size, **kwargs), epsilon=epsilon, batch_size=batch_size) result_df = pd.DataFrame(result).T result_df["K"] = result_df.index result_df["method"] = name withopen(filename, "wb") asfile: pickle.dump(result_df, file)return result_df
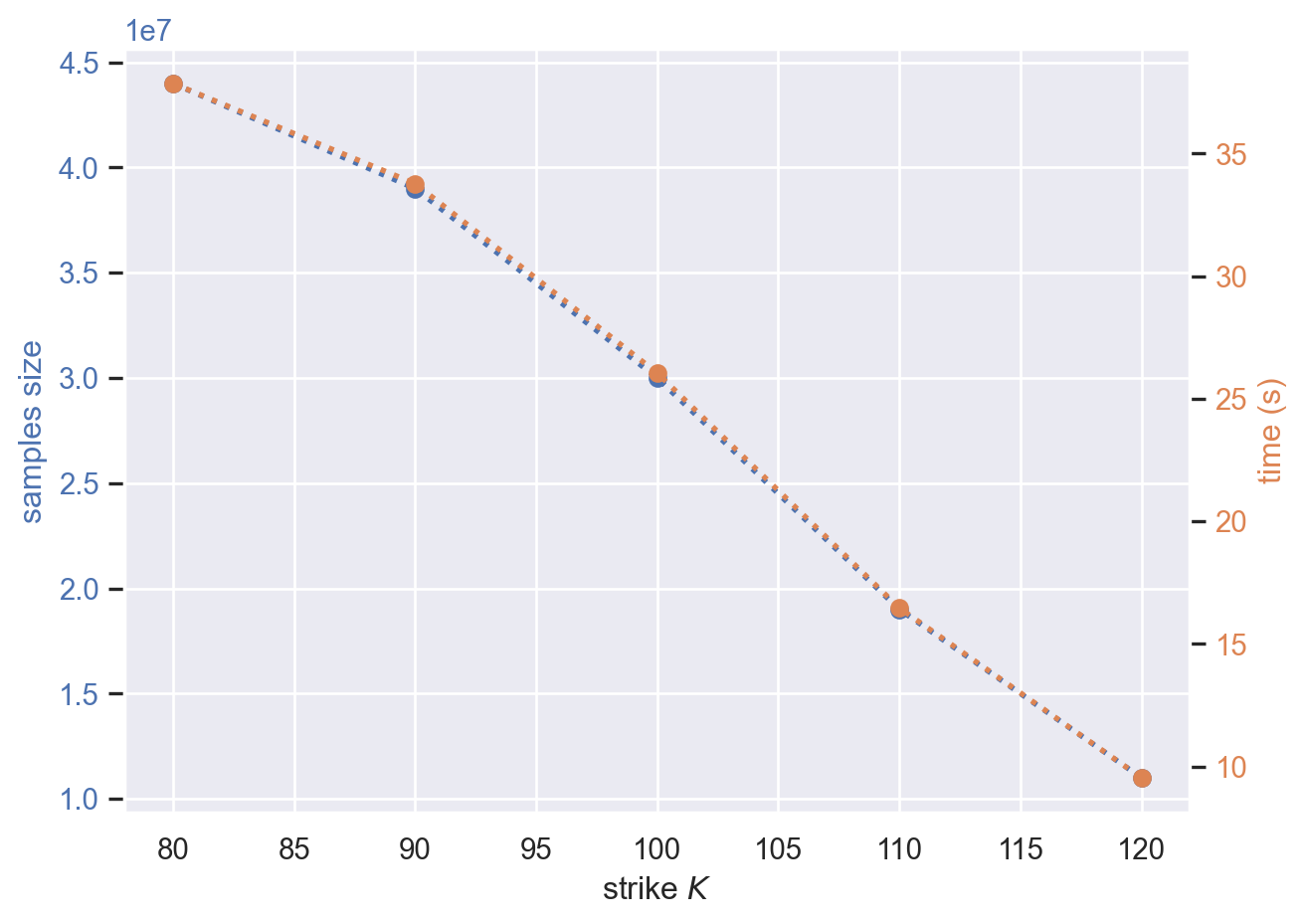
On vérifie que le temps d’execution est proportionnel au nombre de d’échantillons utilisé dans l’estimateur Monte Carlo.
Note
Avant de lancer des gros calculs, pensez à vérifier que votre algorithme se comporte comme attendu. Ici l’estimateur Monte Carlo est linéaire donc le temps d’execution doit être proportionnel au au nombre de simulations. Si ce n’est pas le cas il y a un problème d’implémentation ou de gestion de la mémoire)
PyTorch est une bibliothèque open-source de calcul scientifique et d’apprentissage automatique largement utilisée dans la recherche et l’industrie. Elle est particulièrement conçue pour le développement et l’entraînement de modèles d’apprentissage profond, mais elle offre également des outils puissants pour la simulation et les probabilités numériques.
PyTorch repose sur la manipulation de tenseurs, des structures multidimensionnelles similaires à des matrices, qui permettent des opérations rapides et efficaces sur de grandes quantités de données.
PyTorch peut exécuter des calculs sur GPU, offrant ainsi des performances considérablement améliorées pour les tâches exigeantes en ressources.
Différentiation automatique (Autograd): L’un des points forts de PyTorch est son système de différenciation automatique, qui simplifie le calcul des gradients pour optimiser des fonctions complexes. Cela est essentiel pour l’entraînement des modèles d’apprentissage profond.
Pour passer d’un code NumPy à un code PyTorch il faut remplacer les objets np.ndarray par des objets torch.tensor. Une nouveauté est la notion de device.
Important
En PyTorch, un device désigne l’endroit où les calculs et les données sont stockés et exécutés. En pratique il y a essentiellement 2 types de device:
CPU (Central Processing Unit) : l’unité de traitement standard de l’ordinateur.
GPU (Graphics Processing Unit) : une unité de traitement spécialisée, capable d’exécuter des opérations massivement parallèles.
Le type de données stockées dans le torch.tensor doit être compatible avec le device utilisé. Dans la suite on utilise le type torch.float32 pour que le code suivant puisse être executé sur un GPU Nvidia d’il y a quelques années ou sur le GPU intégré de la puce ARM d’apple.
import torchdtype = torch.float32device = torch.device("cpu")rng_torch = torch.Generator(device=device)bs_torch = { key: torch.tensor(item, dtype=dtype, device=device) iftype(item) is np.ndarray else item for key, item in bs.items() }
Il faut remplacer la fonction phi par la version pytorch tout simplement en remplaçant les appels np.exp et np.einsum par les versions torch.exp et torch.einsum.
Dans certains cas, la fonction pytorch a le même nom que la fonction numpy mais les appels autorisés peuvent être différents par exemple la fonction np.maximum peut comparer un objet np.ndarray et un scalaire alors que la version pytorch torch.maximum fair la comparaison uniquement entre 2 objets torch.tensor.
Une alternative ici est d’utiliser la fonction ReLU (qui est simplement la fonction partie positive) dans torch.nn.functional.
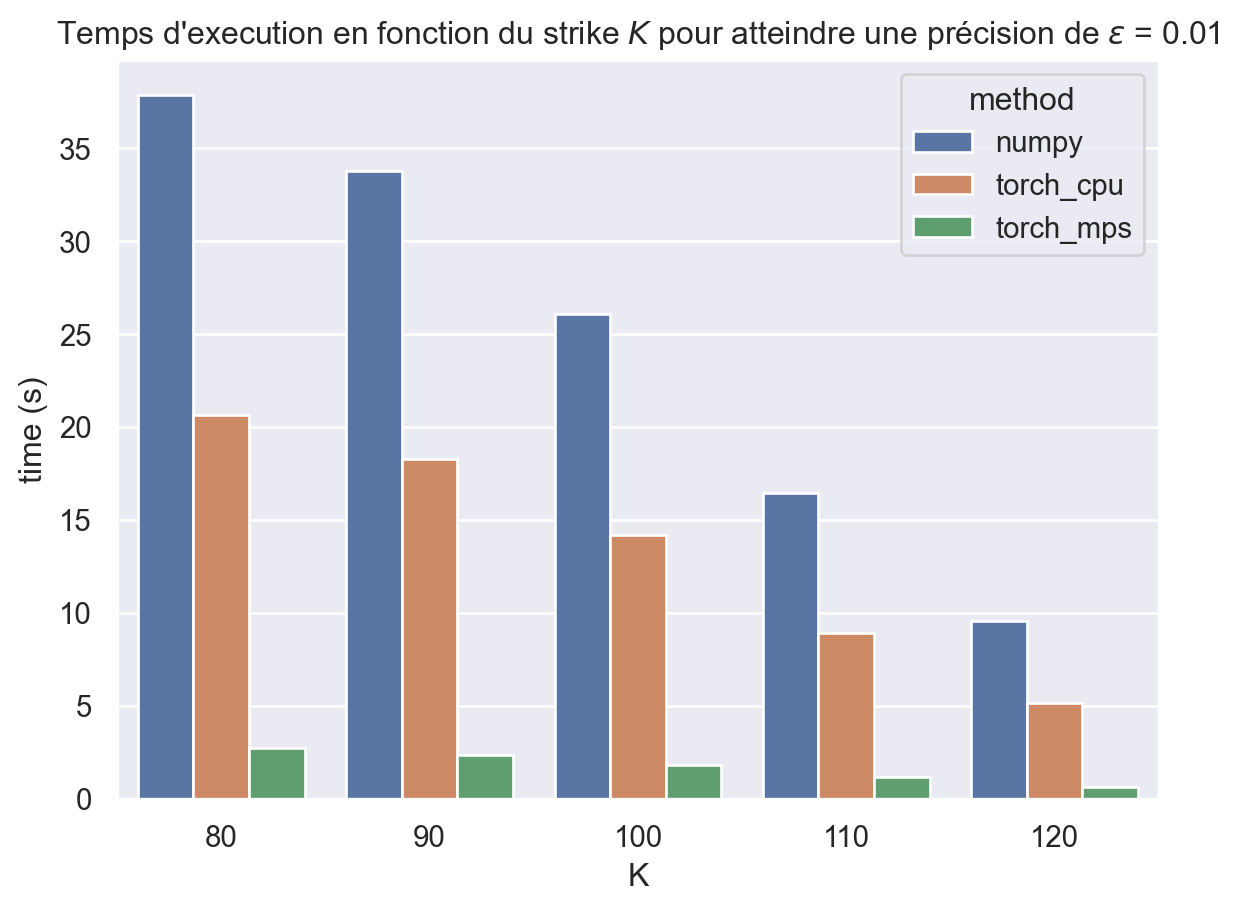
On remarque que le code pytorch sur CPU est 2 fois plus rapide que le code numpy. C’est étonnant car les deux codes tournent sur le CPU et devraient donc donner des résultats équivalents. Sur votre machine vous avez peut-être des temps comparables. Les différences qui peuvent expliquer les temps de calculs sont
le générateur de nombres pseudo-aléatoires (différence entre rng et rng_torch)
le type utilisé ici dtype est sur 32 bits alors que le type numpy est 64 bits
2.2.2.1 Changement de device
Cette section ne peut s’executer que si vous avec un ordinateur Apple récent (puce ARM). Il est facilement executable sur un carte graphique Nvidia en changeant le device, par exemple
device = torch.device("cuda")
Note
Le device mps dans PyTorch fait référence à l’utilisation du backend Metal Performance Shaders (MPS), qui est une technologie développée par Apple. Elle permet d’exécuter des calculs tensoriels sur les GPU des appareils Apple, comme les Mac équipés de processeurs Apple Silicon (M1, M2, etc.) ou d’autres GPU compatibles Metal. C’est une alternative à CUDA mais encore partielle (toutes les fonctionnalités PyTorch ne sont pas encore être entièrement prises en charge pour MPS) et les performances sont inférieures à celles des GPU NVIDIA haut de gamme utilisant CUDA.
Dans le code précédent on doit modifié l’objet bs_torch pour déplacer les données des torch.tensor vers le device utilisé. Les fonctions phi_torc et sampling_payoffs_torch n’ont pas besoin d’être réécrites, il suffit de changer les arguments!
device = torch.device("mps")rng_torch = torch.Generator(device=device)bs_torch = { key: torch.tensor(item, dtype=dtype, device=device) iftype(item) is np.ndarray else item for key, item in bs.items() }
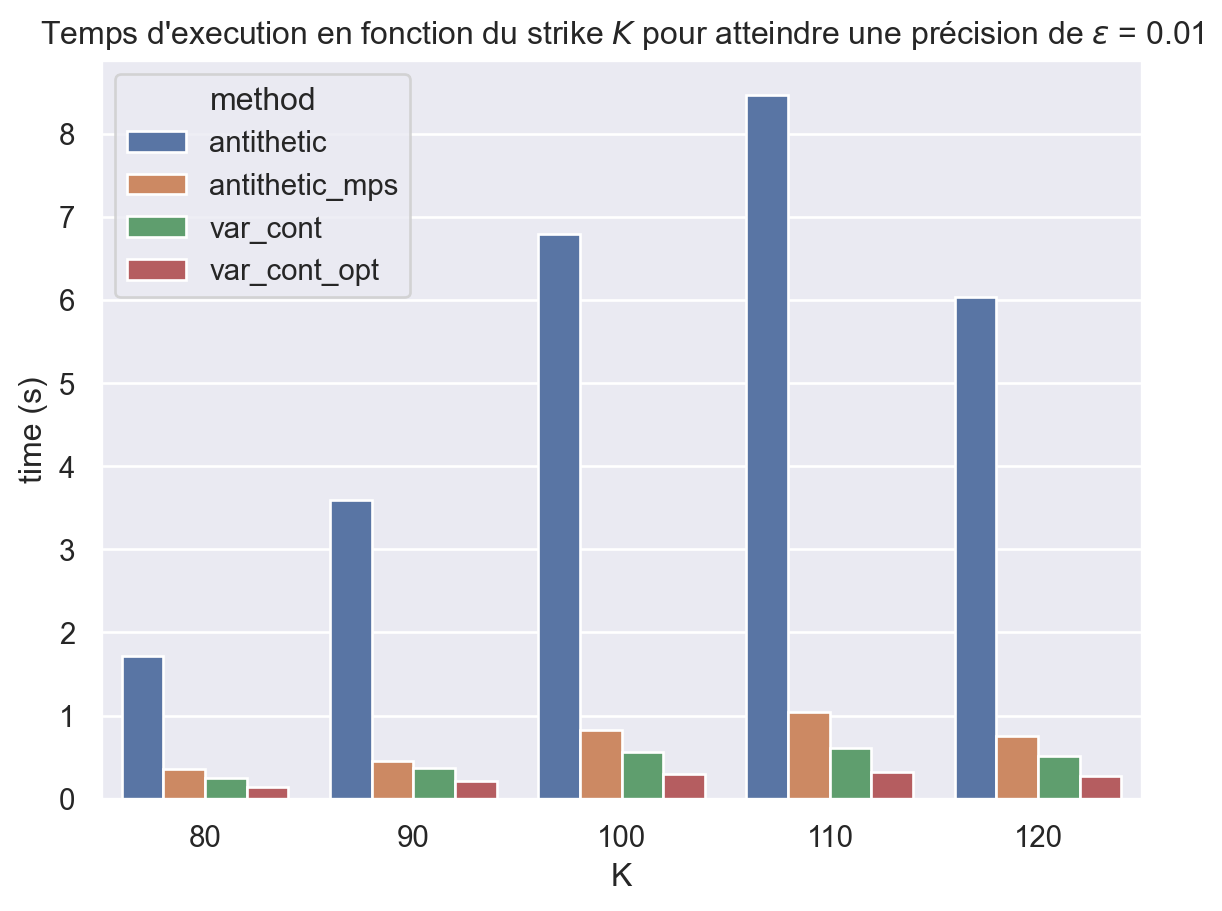
result = pd.concat([ result_numpy, result_torch_cpu, result_torch_mps ])ax = sns.barplot(data=result, x="K", y="time (s)", hue="method")ax.set_title(fr"Temps d'execution en fonction du strike $K$ pour "+fr"atteindre une précision de $\epsilon$ = {epsilon}");
2.3 Méthodes de réduction de variance
On rappelle que le modèle est codé à travers la fonction phi. Cette fonction ne sera pas modifiée dans la suite. Le payoff est donné par une fonction \(g:\mathbf{R}^d \to \mathbf{R}_+\) et le code est fait dans la fonction sampling_payoffs. On va implémenter les méthodes des réduction de variance vues en cours en modifiant la fonction sampling_payoffs.
2.3.1 Variables antithétiques
Pour utiliser les variables antithétiques on utilise le fait que \(G \sim \mathcal{N}(0, \operatorname{Id}_d)\) et \(-G\) ont même loi et donc que \[
\mathbf{E} \big[ (g \circ \Phi)(G) \big] = \frac{1}{2}
\mathbf{E} \big[ (g \circ \Phi)(G) + (g \circ \Phi)(-G) \big].
\] Cela suggère d’utiliser la représentation de droite pour écrire un estimateur Monte Carlo de la forme \[
\tilde I_n = \frac{1}{2 n} \sum_{i=1}^n \big( g \circ \Phi(G_i) + g \circ \Phi(-G_i) \big),
\] où \((G_i)_{i \ge 1}\) est une suite i.i.d. de loi \(\mathcal{N}(0, \operatorname{Id}_d)\).
Voici le code modifié pour implémenter les variables antithétiques.
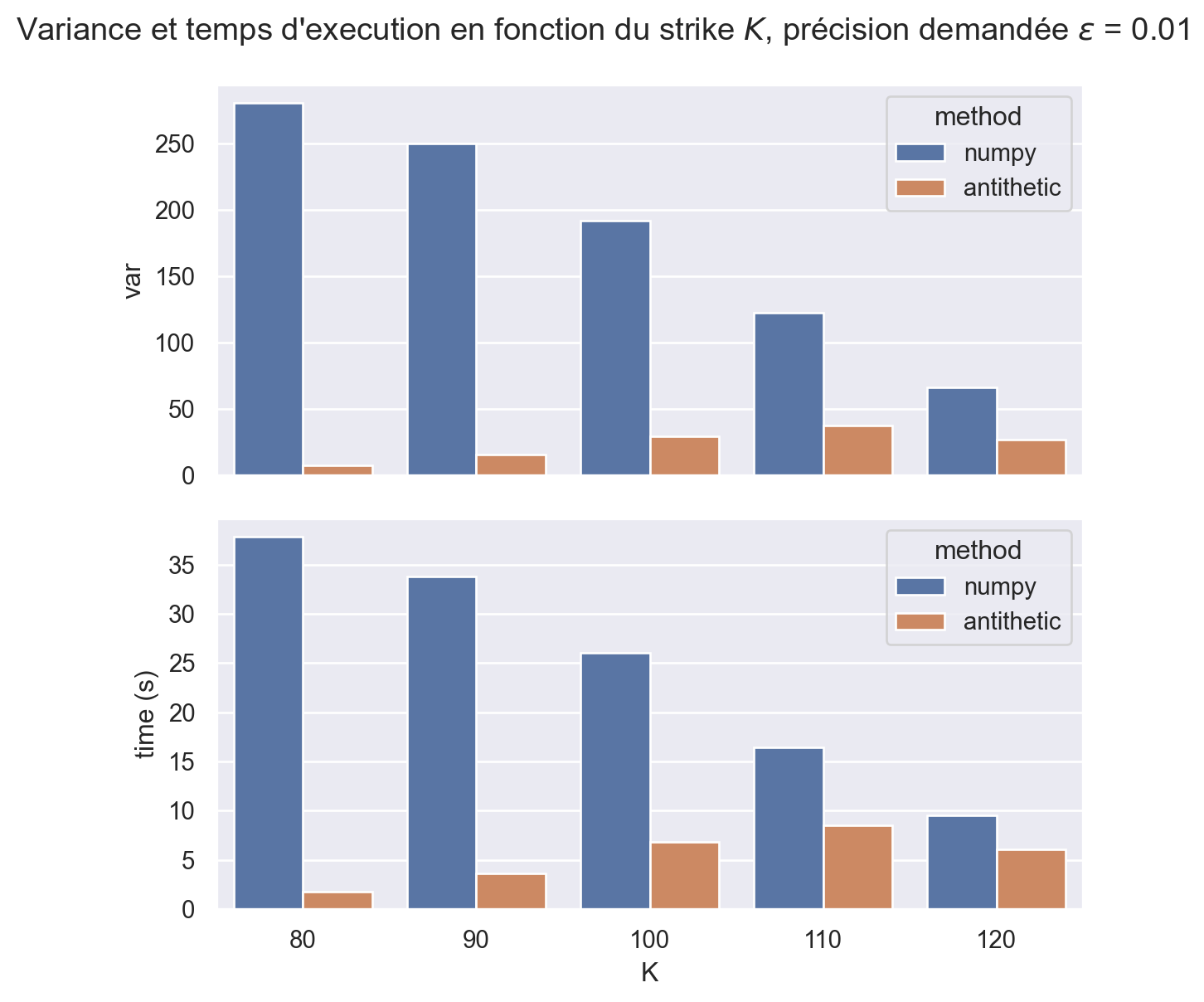
Dans la suite comme le nombre d’échantillons va diminuer (car on utilise des méthodes de réduction de variance) on change le batch_size dans le Monte Carlo adaptatif: on passe de \(1\,000\,000\) à \(100\,000\).
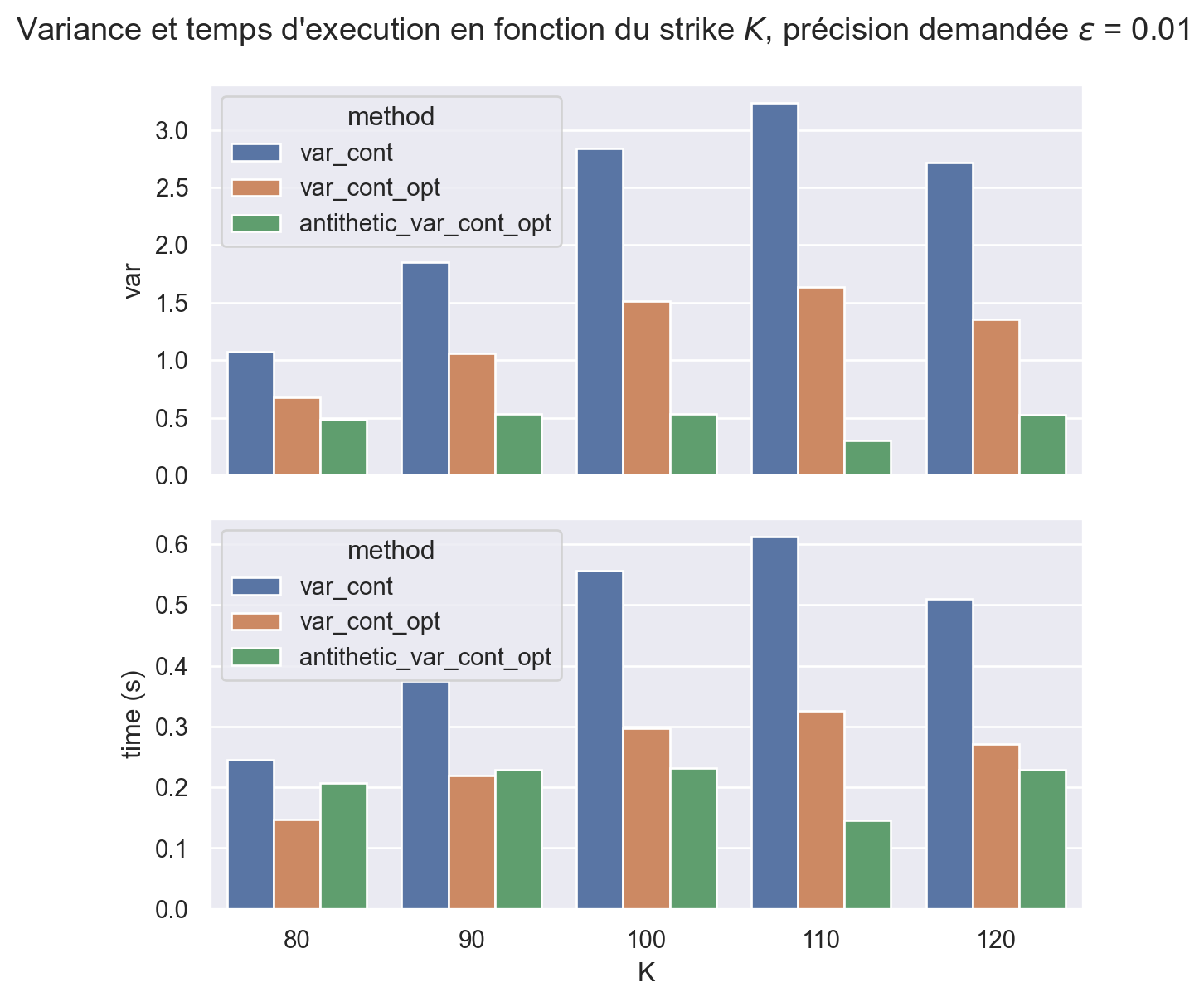
result = pd.concat([ result_numpy, result_antithetic ])fig, (ax1, ax2) = plt.subplots(nrows=2, ncols=1, figsize=(6.4,6.4), sharex=True, layout="tight")sns.barplot(data=result, x="K", y="var", hue="method", ax=ax1)sns.barplot(data=result, x="K", y="time (s)", hue="method", ax=ax2)fig.suptitle(fr"Variance et temps d'execution en fonction du strike $K$, "+fr"précision demandée $\epsilon$ = {epsilon}");
2.3.1.1 Passage en pytorch
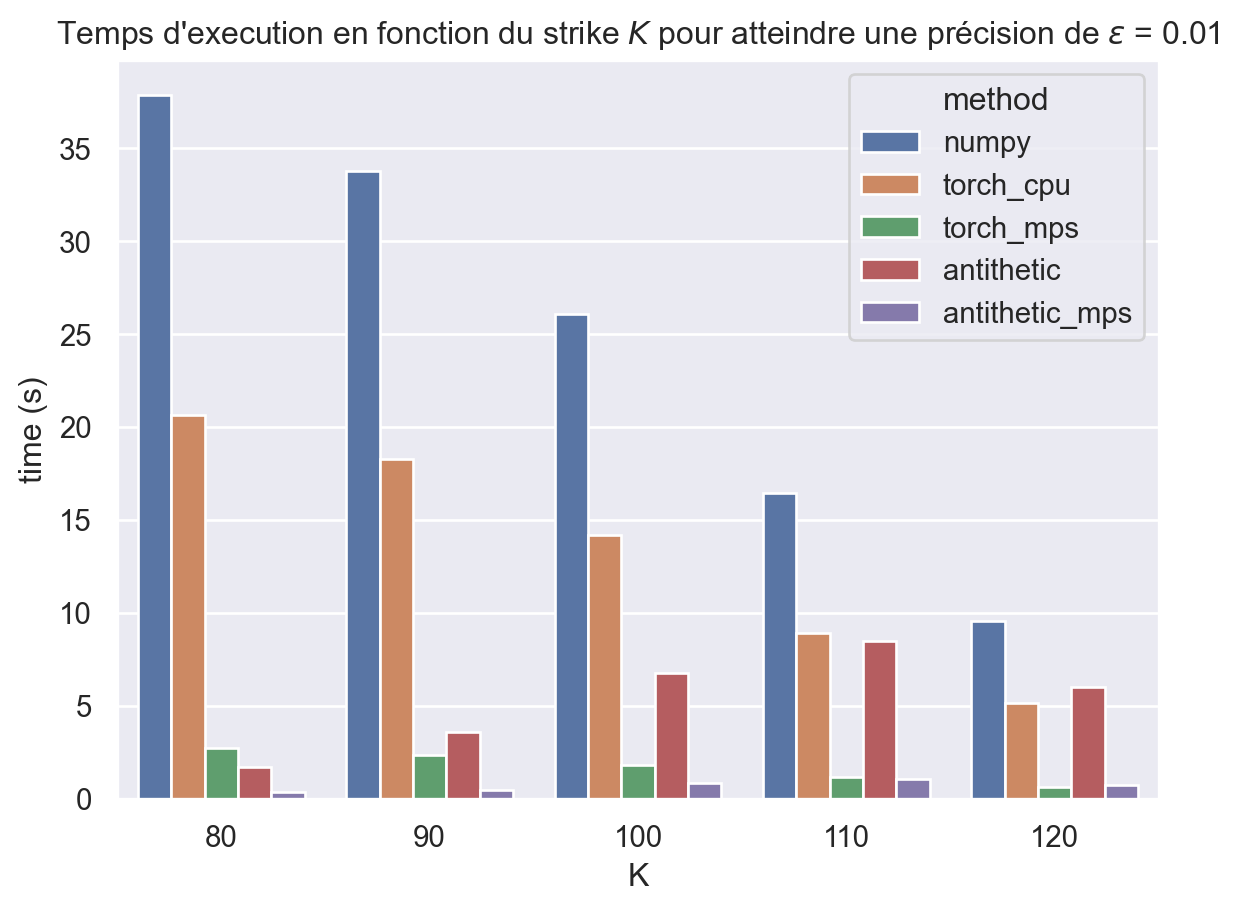
Pas de difficulté particulière ici, si suffit de modifier la fonction sampling_payoffs_torch pour évaluer 2 fois \(g \circ \Phi\) (via relu, torch.mean et phi_torch).
result = pd.concat([ result_numpy, result_torch_cpu, result_torch_mps, result_antithetic, result_antithetic_mps ])ax = sns.barplot(data=result, x="K", y="time (s)", hue="method")ax.set_title(fr"Temps d'execution en fonction du strike $K$ pour "+fr"atteindre une précision de $\epsilon$ = {epsilon}");
2.3.2 Variable de contrôle
On rappelle que le prix d’un Call dans un modèle de Black-Scholes en dimension 1, le prix est donnée par une formule fermée. Pour une option Basket (en dimension \(d \ge 2\)) on approche le prix par Monte Carlo mais on peut utiliser des approximations pour trouver un produit unidimensionnel proche du produit Basket. Ces approximations servent de variables de contrôles: on ne rajoute pas une erreur, on retire de la variance…
On rappelle que, en posant \(\mu_i = r - \frac{1}{2}\sigma_i^2\), \[
X = \biggl(\frac{1}{d} \sum_{i=1}^d S^i_0 e^{\mu_i T + \sigma_i \sqrt{T} \tilde G_i} - K\biggr)_+
\] et en introduisant \(a^i_0 = \frac{S^i_0}{\sum_{j=1}^d S^j_0}\) (t.q. \(\sum a^i_0 = 1\)) et \(\bar S_0 = \frac{1}{d} \sum_{i=1}^d S^i_0\) on a \[
X = \biggl(\bar S_0 \sum_{i=1}^d a^i_0 e^{\mu_i T + \sigma_i \sqrt{T} \tilde G_i} - K\biggr)_+.
\] La variable de contrôle proposée est obtenue en échangeant l’exponentielle et la moyenne pondérée par les poids \(\big(a^i_0\big)_{i=1,\dots,d}\): \[
Y = \bigl(\bar S_0 e^Z - K\bigr)_+
\quad \text{avec} \quad
Z = \sum_{i=1}^d a^i_0 \big(\mu_i T + \sigma_i \sqrt{T} \tilde G_i\big)
\] La variable aléatoire \(Z\) suit une loi gaussienne \(Z \sim \mathcal{N}(m T, s^2 T)\) avec \[
m = \sum_{i=1}^d a^i_0 \mu_i
\quad \text{et} \quad
s^2 = \sum_{i=1}^d \Big( \sum_{j=1}^d a^i_0 \sigma_i L_{ij} \Big)^2.
\] Ainsi l’espérance de la variable de contrôle \(Y\) est connue par la formule de Black-Scholes, car elle correspond au prix d’un call de strike \(K\) d’un actif Black-Scholes de dimension 1, de valeur initiale \(\bar S_0\), de taux \(\rho = m+\frac{1}{2} s^2\) et de volatilité \(s\) (à un facteur d’actualisation près… attention à ça). On a donc \[
e^{-\rho T} \mathbf{E} \big[ Y \big] = P_{\text{BS}}\big(\bar S_0, \rho, s, T, K\big),
\] où \[
P_{\text{BS}}\big(x, r, \sigma, T, K\big) = x F_{\mathcal{N}(0,1)}(d_1) - K e^{-r T} F_{\mathcal{N}(0,1)}(d_2),
\] avec \(F_{\mathcal{N}(0,1)}\) est la fonction de répartition de la loi normale centrée réduite et la notation \[
d_1 = \frac{1}{\sigma \sqrt{T}} \Big( \log\big( \frac{x}{K} \big)
+ \big(r + \frac{\sigma^2}{2}\big) T \Big)
\quad \text{et} \quad
d_2 = d_1 - \sigma \sqrt{T}
\]
Code de la fonction black_scholes_call
def black_scholes_call(S0: float, K: float, T: float, r: float, sigma: float) ->float:""" Calcule le prix d'un Call européen dans le modèle de Black-Scholes. Args: - S0 (float): Prix actuel de l'actif sous-jacent. - K (float): Prix d'exercice du Call. - T (float): Temps jusqu'à l'échéance en années. - r (float): Taux d'intérêt sans risque. - sigma (float): Volatilité du sous-jacent. Returns: - float: Prix du Call européen. """# Calcul des paramètres d1 et d2 d1 = (math.log(S0/K) + (r +0.5*sigma**2)*T) / (sigma*math.sqrt(T)) d2 = d1 - sigma*math.sqrt(T)# Calcul du prix du Call call_price = S0*sps.norm.cdf(d1) - K*math.exp(-r*T)*sps.norm.cdf(d2)return call_price
Note
On code une fonction payoffs_control qui renvoie des réalisation de la variable de contrôle centrée \(\tilde Y = Y - \mathbf{E}[Y]\). Il est important de noter que
l’espérance est calculée en utilisant la formule fermée obtenue car \(Z \sim \mathcal{N}(m T, s^2 T)\)
les réalisations de \(Y\) (et donc de \(Z\)) sont obtenues par transformation de \(G\) et donc la fonction payoffs_control doit prendre comme argument l’objet Gn
Lorsqu’on travaille avec une variable de contrôle centrée \(\tilde Y\), la formule pour obtenir la combinaison linéaire entre le payoff \(X\) et la variable de contrôle \(\tilde Y\) se simplifie en \[
\lambda^* = \frac{\mathbf{E}\big[X \tilde Y]}{\mathbf{E}[\tilde Y^2]}.
\] On rappelle que c’est le paramètre \(\lambda^* \in \mathbf{R}\) solution de \[
\lambda^* = \operatorname{argmin}_{\mathbf{R}} \operatorname{var}(X - \lambda \tilde Y).
\] Ainsi on peut écrire un estimateur de \(\lambda^*\) comme le ratio \[
\lambda_n = \frac{\sum_{i=1}^n X_i \tilde Y_i}{\sum_{i=1}^n \tilde Y_i^2}
\]
Ici on utilise une variable cntxt (un dictionnaire) pour stocker les quantités \(\sum_{i=1}^n X_i \tilde Y_i\) et \(\sum_{i=1}^n \tilde Y_i^2\) qui sont mis à jour à chaque itération de la fonction monte_carlo_adaptive. Cette variable doit être initialisée avant le premier appel de sampling_payoffs_control_variate_opt, il faut donc adapter la fonction run.
Code adapté de la fonction run
name ="var_cont_opt"function = sampling_payoffs_control_variate_optfilename ="02_data/"+ name +".pkl"if os.path.exists(filename): withopen(filename, "rb") asfile: result_df = pickle.load(file)else: result = {} for K in [80, 90, 100, 110, 120]: cntxt = { "lambda_numerator": 0., "lambda_denominator": 1e-7 } result[K] = monte_carlo_adaptive(lambda size: function(K, size, bs, rng), epsilon=epsilon, batch_size=batch_size) result[K]["lambda"] = cntxt["lambda"] result_df = pd.DataFrame(result).T result_df["K"] = result_df.index result_df["method"] = name withopen(filename, "wb") asfile: pickle.dump(result_df, file)result_varcont_opt = result_dfresult_varcont_opt
mean
var
ci_size
samples_size
time (s)
lambda
K
method
80
27.767191
0.675417
0.009300
120000.0
0.146850
1.038284
80
var_cont_opt
90
19.393642
1.062212
0.009522
180000.0
0.219193
1.056107
90
var_cont_opt
100
12.265135
1.513713
0.009845
240000.0
0.297285
1.094868
100
var_cont_opt
110
6.962580
1.637633
0.009838
260000.0
0.325992
1.129514
110
var_cont_opt
120
3.558439
1.357368
0.009737
220000.0
0.270659
1.169945
120
var_cont_opt
result = pd.concat([ result_antithetic, result_antithetic_mps, result_varcont, result_varcont_opt ])ax = sns.barplot(data=result, x="K", y="time (s)", hue="method")ax.set_title(fr"Temps d'execution en fonction du strike $K$ pour "+fr"atteindre une précision de $\epsilon$ = {epsilon}");
2.3.3 Combinaison des 2 méthodes
Il est possible de combiner plusieurs méthodes de réduction de variance. Ici on fait une variable de contrôle (optimale) sur des variables antithétiques.