import mathimport numpy as npimport torchdev_cpu = torch.device("cpu")rng_cpu = torch.Generator(device=dev_cpu)dev_mps = torch.device("mps")rng_mps = torch.Generator(device=dev_mps)from scipy import statsimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snssns.set_theme()
On commence par une première section sur la simulation exacte du processus d’Ornstein-Uhlenbeck. Il s’agit d’illustrer que le choix des instructions peut avoir un impact sur la performance des simulations et d’illustrer la différentiation automatique du module pytorch.
4.1 Processus d’Ornstein-Uhlenbeck
On considère \((X_t)_{t \in [0,T]}\) processus à valeurs dans \(\mathbf{R}\) solution de l’EDS \[
\operatorname{d}\! X_t = \lambda (\mu - X_t) \operatorname{d}\! t + \sigma \operatorname{d}\! W_t, \quad X_0 = x \in \mathbf{R},
\] où \(\lambda > 0\), \(\mu, \sigma \in \mathbf{R}\).
Le processus \((Y_t)_{t \in [0,T]}\) est une intégrale de Wiener, donc un processus de Markov et un processus Gaussien de fonction moyenne \(m_Y(t) = x-\mu\) et de fonction de covariance \[
\begin{aligned}
K_Y(s, t) &= \operatorname{cov}(Y_s, Y_t) = \sigma^2 \mathbf{E}\bigg[\int_0^s e^{\lambda u} \operatorname{d}\! W_u \int_0^t e^{\lambda u} \operatorname{d}\! W_u \bigg], \\
&= \frac{\sigma^2}{2 \lambda} \big( e^{2 \lambda \min(s,t)} - 1 \big).
\end{aligned}
\] En particulier, \[
\forall 0 \le s \le t, \quad \mathcal{L}\big(Y_t| \sigma(Y_u, u \le s)\big)
\sim \mathcal{N}\Bigl( Y_s ; \frac{\sigma^2}{2 \lambda} \bigl( e^{2 \lambda t} - e^{2 \lambda s}\bigr) \Bigr)
\]
On en déduit que \((X_t)_{t \in [0,T]}\) est aussi un processus Gaussien de fonction moyenne \(m_X\) et de fonction de covariance \(K_X\) définies par \[
m_X(t) = \mu + (x-\mu) e^{-\lambda t} \quad \text{et} \quad
K_X(s, t) = \frac{\sigma^2}{2 \lambda} e^{-\lambda (s+t)} \big( e^{2 \lambda \min(s,t)} - 1 \big).
\] En particulier, \[
\forall 0 \le s \le t, \quad \mathcal{L}\big(X_t| \sigma(X_u, u \le s)\big)
\simeq \mathcal{N}\Bigl( \mu + (X_s-\mu) e^{-\lambda(t-s)} ; \frac{\sigma^2}{2 \lambda} \bigl( 1 - e^{-2\lambda(t-s)} \bigr) \Bigr)
\]
Avertissement
On illustre dans ce notebook un peu de programmation orientée objet (POO). En Python on peut facilement écrire un code sans avoir recourt à de la POO (définition de classe, etc.) mais dans certains cas la syntaxe POO est agréable. Voici un exemple de classe ornstein_uhlenbeck dont on définira les méthodes direct_simulation et recursive_simulation dans la suite.
class ornstein_uhlenbeck: def__init__(self, lambd, mu, sigma): self.lambd = lambdself.mu = muself.sigma = sigmadef__repr__(self): returnf"Ornstein-Uhlenbeck de paramètres: "+\f"lambda = {self.lambd}, mu = {self.mu}, sigma = {self.sigma}"# déclaration pas nécessaire mais habitude du C++def direct_simulation(self, x0, final_time, gaussians):passdef recursive_simulation(self, x0, final_time, gaussians):pass
Note
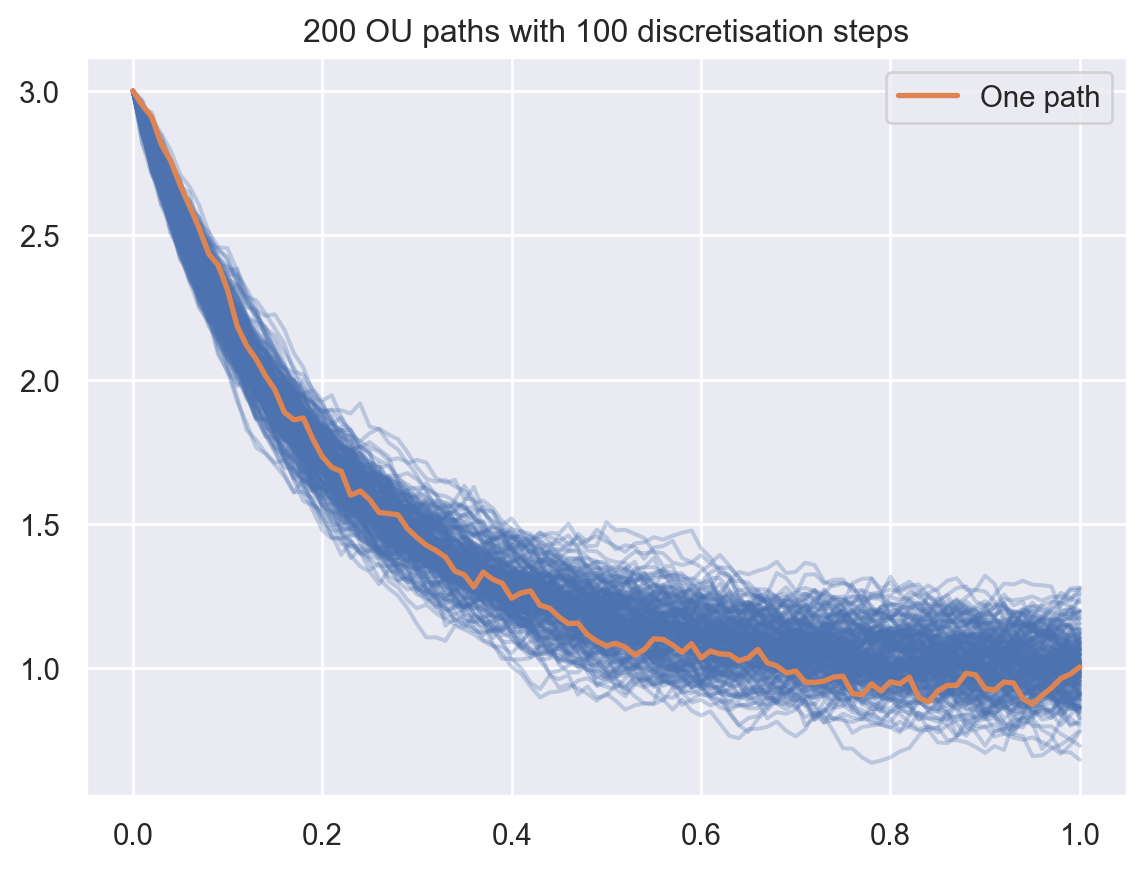
Dans la suite on se donne les paramètres suivants: \(\lambda = 5\), \(\mu=1\), \(\sigma =0.3\), \(X_0 = 3\) et \(T = 1\) de sorte que la loi de \(X_T\) est \(\mathcal{N}\big( \mu + (x-\mu) e^{-\lambda T}; \frac{\sigma^2}{2\lambda} (1-e^{-2 \lambda T}) \big)\).
ou = ornstein_uhlenbeck(lambd=5, mu=1, sigma=0.3)print(ou)x0, T =3.0, 1print(f"Point initial x0 = {x0} et temps terminal T = {T}")mean_T = ou.mu + (x0-ou.mu) * math.exp(-ou.lambd*T)var_T = ou.sigma**2/ (2*ou.lambd) * (1- math.exp(-2*ou.lambd*T))print(f"mean: {mean_T}\t var: {var_T}")
Ornstein-Uhlenbeck de paramètres: lambda = 5, mu = 1, sigma = 0.3
Point initial x0 = 3.0 et temps terminal T = 1
mean: 1.013475893998171 var: 0.008999591400632136
4.1.1 Deux codes (équivalents ?) de simulation
On compare ici deux codes possibles pour simuler des trajectoires du processus d’Ornstein-Uhlenbeck:
simulation de \(Y_{t_k}\) via ses accroissements et on récupère \(X_{t_k}\)
contruction de \(X_{t_{k+1}}\) à partir de \(X_{t_k}\)
4.1.1.1 Construction directe, via le processus \(Y\)
On définit la méthode direct_simulation de la classe ornstein_uhlenbeck qui permet la construction d’un ensemble de trajectoires à partir d’un tenseur gaussians qui contient \(M \times N\) gaussiennes centrées réduites (\(M\) le nombe de trajectoires et \(N\) qui règle le pas de discrétisation \(h = T/N\)).
L’implémentation est la suivante: on simule les accroissements de \((Y_t)_{t \in [0,T]}\) aux instants \(t_k = k h\), puis on reconstruit les \(Y_{t_k}\) (via cumsum) et on obtient \(X_{t_k}\) à partir de \(Y_{t_k}\).
On définit la méthode recursive_simulation de la classe ornstein_uhlenbeck qui implémente la simulation des trajectoires en utilisant une boucle for pour construire itérativement \(X_{t_{k+1}}\) à partir de \(X_{t_k}\) (les \(M\) trajectoires en même temps).
La boucle for sur les itérations en temps est acceptable, par contre en aucun cas il faut faire une boucle sur les trajectoires (avec les modules numpy ou pytorch).
65 ms ± 1.42 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
71.3 ms ± 1.28 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
4.97 ms ± 21.8 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
5.46 ms ± 203 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
cpu
mps
direct
65.008 ms
4.9743 ms
recursive
71.25 ms
5.4635 ms
Note
Exercice: reprendre ces fonctions en inversant les axes. Que constatez-vous ?
Le module autograd de pytorch est un outil puissant qui implémente la différentiation automatique dite backward ou adjointe (AAD). C’est une méthode efficace pour calculer le gradient d’une fonction de \(\mathbf{R}^m \to \mathbf{R}\) ou la matrice Jacobienne d’une fonction de \(\mathbf{R}^m \to \mathbf{R}^n\).
Contrairement aux méthodes numériques classiques, comme les différences finies ou les méthodes des chocs,la différentiation automatique repose sur une approche analytique basée sur les règles de dérivation des fonctions composées.
PyTorch construit un graphe computationnel dynamique (coût assez cher) lors de l’exécution du code : chaque opération est enregistrée avec ses dépendances, ce qui permet de calculer les dérivées exactes de manière rétroactive à partir des résultats finaux.
4.1.2.2 Application à un problème de sensibilités Monte Carlo
Soit \(f: \mathbf{R} \to \mathbf{R}\) la fonction définie par \[
f(x) = \mathbf{E} \bigl[ X^2_T | X_0 = x \bigr].
\] Par le calcul précédent on sait que la fonction \(f\) est quadratique et on connait sa dérivée \(f'\). Plus précisément on a \[
f(x) = \big((x-\mu) e^{-\lambda T} + \mu \big)^2 + \frac{\sigma^2}{2\lambda}(1 - e^{-2 \lambda T})
\] et donc \(f'(x) = 2 x e^{-\lambda T}\).
Le but est de faire un code de différentiation automatique qui calcule automatiquement la sensibilité de \(f\) par rapport à la variable \(x\) (sans utiliser la formule explicite…)
n_steps, n_paths =100, 100000## on crée un tensor x0_ avec l'attribut `requires_grad=True` x0_ = torch.tensor(float(x0), device=dev_cpu, requires_grad=True)## on calcule une quantité qui dépend de x0: évaluation forward ## dans cette phase il y a création du graphe de calcul gaussians = torch.randn((n_steps, n_paths),device=dev_cpu,generator=rng_cpu)sample = ou.direct_simulation(x0_, T, gaussians)f_x0 = (sample[-1]**2).mean()## évaluation rétrograde en utilisant le graphe de calcul ## pour évaluer la dérivée qui sera stockée dans le champ .grad de x0_f_x0.backward()df_x0 = x0_.gradprint(f"Approximation AAD: f({x0}) = {f_x0.item():.5}\t"+\f"f'({x0}) = {df_x0.item():.5}")
Comment obtenir un intervalle de confiance pour f'(3) ? En fait en échangeant dérivation et espérance et en notant \(X_T^x\) la solution issue de \(x\) en zéro (\(X_0 = x\)) on a aussi la représentation \[
f(x) = \mathbf{E} \Big[ (X^x_T)^2 \Big] \quad \text{et} \quad
f'(x) = \mathbf{E} \Big[ \frac{\partial}{\partial x} (X^x_T)^2 \Big].
\] Ainsi on a envie de dériver (mettre en oeuvre l’AAD) sous le signe somme c’est à dire sur les réalisations de \(((X^{(j), x}_T)^2)_{1 \le j \le M}\) utilisées dans l’estimateur Monte Carlo \(\frac{1}{M} \sum_{j=1}^M (X^{(j), x}_T)^2\).
Note
Etant donné un échantillon i.i.d. de variables aléatoires réelles \((Z^{(j),x})_{1 \le j \le M}\) qui dépendent d’un paramètre \(x \in \mathbf{R}\) on veut calculer \(\partial_x Z^{(j),x}\). Pour utiliser le mécanisme VJP (vector jacobian product) de pytorch on utilise la représentation \[
\big(\partial_x Z^{(1),x}, \dots, \partial_x Z^{(M),x} \big) = \big( 1, \dots, 1 \big) J_{x}(g)
\] où \(J_{x}(g)\) est la matrice Jacobienne de \(g:\mathbf{R}^M \to \mathbf{R}^M\) qui au point \((x,\dots,x) \in \mathbf{R}^M\) donne la valeur \((Z^{(1),x}, \dots, Z^{(M),x})\) (les dérivées croisées sont nulles).
Soit \((x_t)_{t \in [0,T]}\) solution d’une EDS \[
\operatorname{d}\! x_t = b(x_t) \operatorname{d}\! t + \sigma(x_t) \operatorname{d}\! W_t, \quad x_0 \in \mathbf{R^d}.
\] On se donne des instants de discrétisation \(0=t_0 < t_1 < \dots < t_N = T\) et dans la suite on spécifie la grille homogène \(t_n = n \frac{T}{N} = n h\) avec \(h = \frac{T}{N}\) appelé le pas de discrétisation.
Schéma d’Euler
On rappelle le schéma d’Euler pour une diffusion: \[
X_{t_{n+1}} = X_{t_n} + b(X_{t_n}) h + \sigma(X_{t_n}) \sqrt{h} G_{n+1}, \quad X_0 = x_0.
\] où dans toute la suite \((G_1,\dots,G_N)\) est un vecteur Gaussien centré réduit (composantes indépendantes). La loi de \(\sqrt{h} G_{n+1}\) est celle de l’accroissement \(W_{t_{n+1}} - W_{t_n}\).
Schéma de Milstein
Avec les mêmes notations que précédemment on définit le schéma de Milstein pour une diffusion (en dimension 1): \[
X_{t_{n+1}} = X_{t_n} + b(X_{t_n}) h + \sigma(X_{t_n}) \sqrt{h} G_{n+1} + \frac{1}{2} (\sigma \sigma')(X_{t_n})(G_{n+1}^2 - 1) h.
\]
On peut aussi utiliser la version équivalente de Newton, schéma avec des propriétés théoriques équivalentes mais sans la dépendance en la dérivée \(\sigma'\)\[
X_{t_{n+1}} = X_{t_n} + b(X_{t_n}) h - \sigma(X_{t_n}) \sqrt{h} + \tilde \sigma_{n+1} \sqrt{h} (G_{n+1} + 1),
\] avec \(\tilde \sigma_{n+1} = \sigma\left(X_{t_n} + \frac{1}{2} \sigma(X_{t_n}) \sqrt{h} \big(G_{n+1} - 1\big) \right)\).
4.2.0.1 Application à Black-Scholes comme “benchmark”
L’équation différentielle stochastique (EDS) est donnée par \[
\operatorname{d}\! x_t = r x_t \operatorname{d}\! t + \sigma x_t \operatorname{d}\! W_t, \quad x_0 > 0
\]
Note
Pour Black-Scholes on connaît la vraie solution de l’EDS et il n’est donc pas nécessaire de faire un schéma de discrétisation. On utilise cet exemple simplement pour illustrer numériquement le comportement des schémas numériques. On rappelle la solution \[
\forall t \in [0,T], \quad x_t = x_0 e^{\left(r - \frac{\sigma^2}{2} \right) t + \sigma W_t}.
\]
class BlackScholes:def__init__(self, r, sigma):self.r = rself.sigma = sigmadef exact_simulation(self, x0, final_time, dW): n_steps, n_paths = dW.shape dt = final_time / n_steps sample = torch.empty((n_steps+1,n_paths), device=dW.device) sample[0] = x0for n inrange(1, n_steps+1): sample[n] = sample[n-1] * torch.exp( (self.r -0.5*self.sigma**2)*dt +self.sigma*dW[n-1])# on pourrait utiliser np.cumprod à la place de cette boucle...return sampledef euler_simulation(self, x0, final_time, dW): n_steps, n_paths = dW.shape dt = final_time / n_steps sample = torch.empty((n_steps+1,n_paths), device=dW.device) sample[0] = x0 for n inrange(1, n_steps+1): sample[n] = sample[n-1] +self.r*sample[n-1]*dt +\self.sigma*sample[n-1]*dW[n-1]return sampledef milstein_simulation(self, x0, final_time, dW): n_steps, n_paths = dW.shape dt = final_time / n_steps sample = torch.empty((n_steps+1,n_paths), device=dW.device) sample[0] = x0for n inrange(1, n_steps+1): sample[n] = sample[n-1] +self.r*sample[n-1]*dt +\self.sigma*sample[n-1]*dW[n-1] +\0.5*self.sigma**2*sample[n-1]*(dW[n-1]**2-dt)return sample
On dit que le schéma est d’erreur forte \(\mathbf{L}^p\), \(p > 1\) d’ordre \(\alpha\) si \[
\left\lVert \sup_{t \in [0,T]} |x_{t} - X^h_{t}|\right\rVert_p = \mathcal{O}(h^\alpha)
\] ou encore \[
\left\lVert \sup_{k \in \{0,\dots,N\}} |x_{t_k} - X^h_{t_k}|\right\rVert_p = \mathcal{O}(h^\alpha)
\]
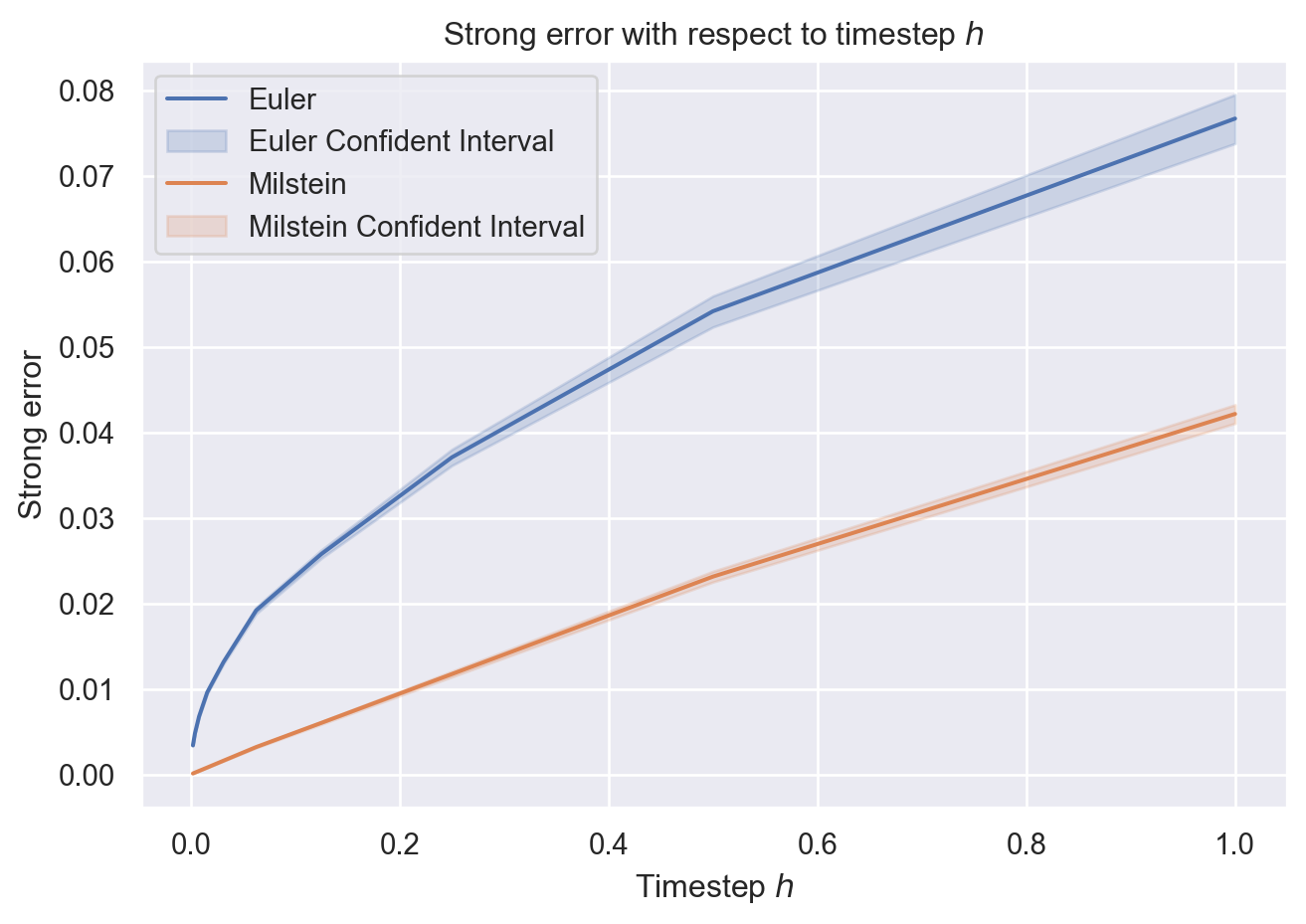
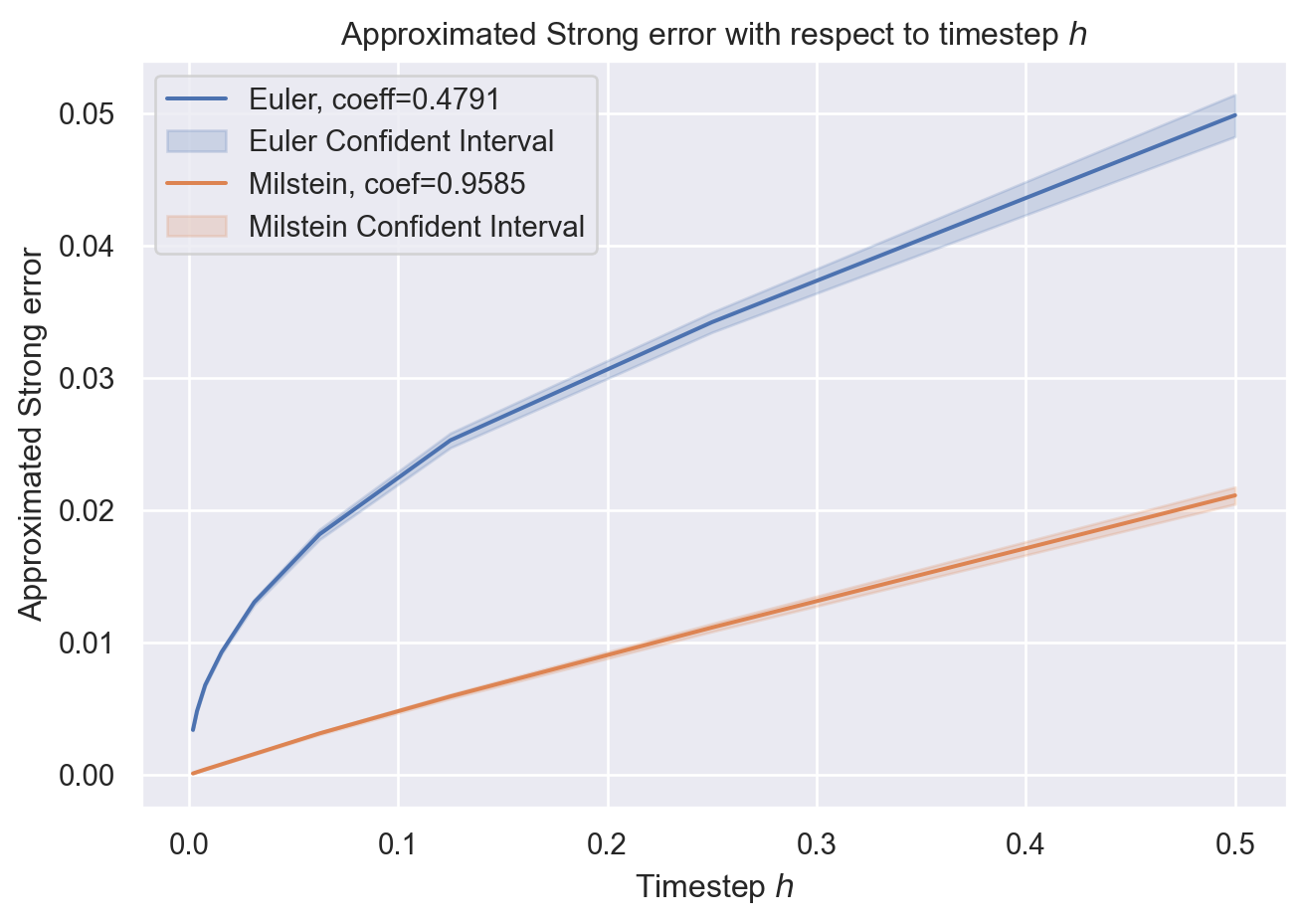
Schéma d’Euler: erreur forte d’ordre \(\frac{1}{2}\) dans tout \(\mathbf{L}^p\) (\(p > 1\)).
Schéma de Milstein: erreur forte d’ordre \(1\) dans tout \(\mathbf{L}^p\) (\(p > 1\)) (dim 1…).
Note
Il s’agit d’une erreur trajectorielle, similaire à l’erreur étudiée en analyse numérique pour un schéma de discrétisation d’une ODE.
Important
Il faut calculer \(\sup_k |x_{t_k} - X^h_{t_k}|\) sur le même événement \(\omega\)i.e. la même trajectoire Brownienne \((W_t)_{t \in [0,T]}\). C’est pour cela qu’on a choisit dans le design du code de séparer la simulation des accroissements Browniens dW et la construction des trajectoires pour chacun des schémas (exact, euler et milstein).
On fait un code pour calculer l’error forte dans \(\mathbf{L}^2\). On utilise un estimateur Monte Carlo de l’erreur \(\mathbf{L}^2\)
On peut vérifier les coefficients \(\alpha = 1/2\) pour Euler et \(\alpha = 1\) pour Milstein en faisant une régression linéaire en échelle logarithmique. Par exemple en utilisant scikit-learn cela donne
Attention encore une fois à bien construire les schémas \((X^h_{kh})_{k=0,\dots,N}\) et \((X^{h/2}_{\frac{kh}{2}})_{k=0,\dots,2N}\) en utilisant la même trajectoire brownienne, de donc le même objet dW.
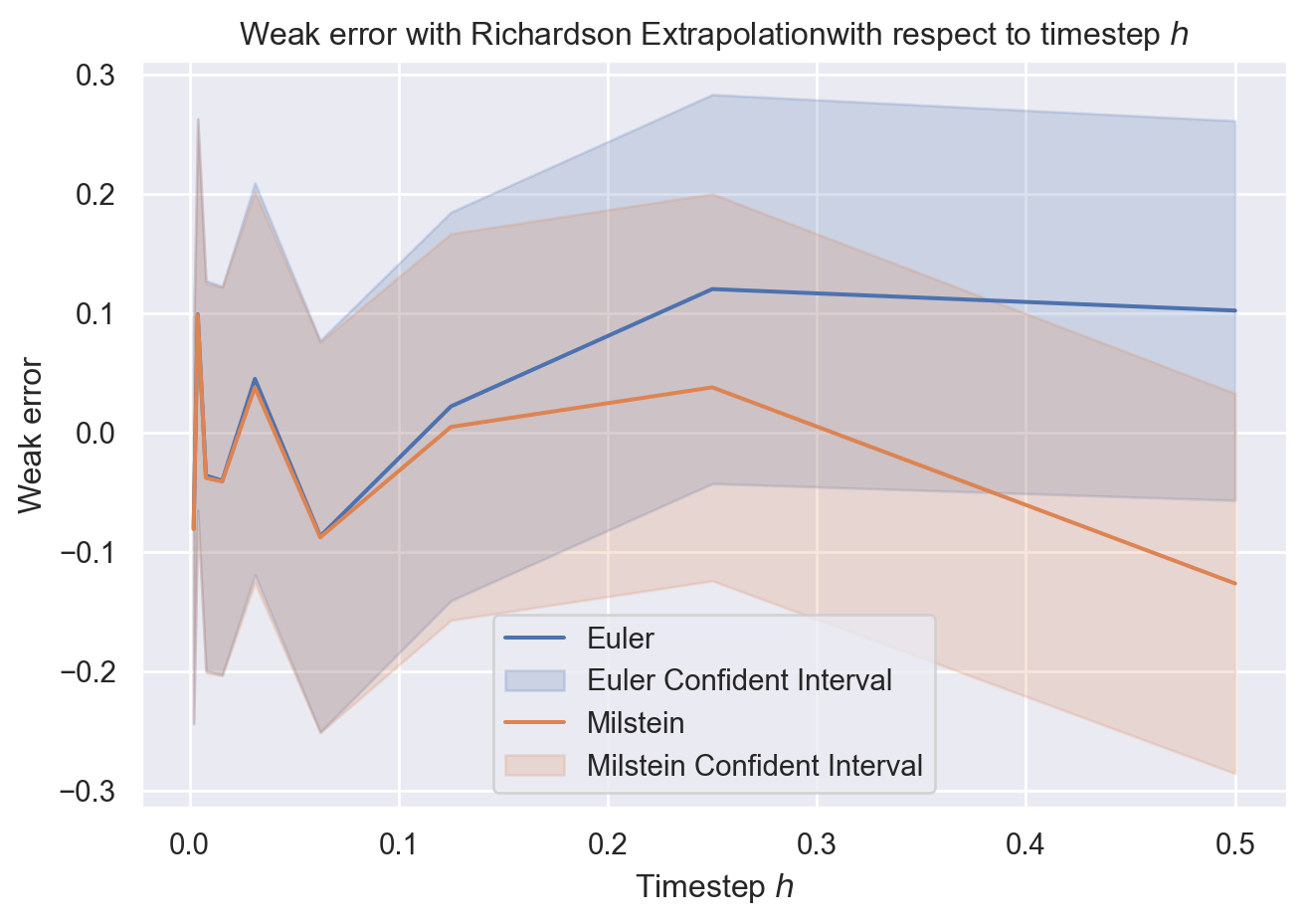
On fera de même pour mettre en oeuvre l’extrapolation de Richardson-Romberg qui permet de gagner un ordre pour l’erreur faible.
On rappelle que l’erreur faible entre la diffusion \(\bigl(x_t\bigr)_{t \in [0,T]}\) et un schéma numérique \(\bigl(X^N_{k}\bigr)_{k=0,\dots, N}\) le long d’une fonction \(\varphi\) vérifie le développement suivant \[
\exists c_1, \dots, c_R, \qquad \mathbb{E} \bigl[ \varphi(x_T) \bigr]
- \mathbb{E} \bigl[ \varphi(X^N_N) \bigr] = \frac{c_1}{N} + \frac{c_2}{N^2} + \cdots + \frac{c_R}{N^R} + \mathcal{O}\bigl( \frac{1}{N^R} \bigr)
\] Il faut de la régularité sur la fonction \(\varphi\) ou bien sur la densité de la loi de \(x_T\) pour obtenir ce résultat.
On illustre les résultats de convergence de l’erreur faible du schéma d’Euler et de Milstein dans le cas d’un pricing d’un call de strike \(K\) à maturité \(T\). Ainsi on a \[
\operatorname{d}\! x_t = r x_t \operatorname{d}\! t + \sigma x_t \operatorname{d}\! W_t, \quad x_0 > 0,
\] et \[
P_{Call}(x_0, T, K) = e^{-r T} \mathbb{E}\bigl[ (x_T - K)_+ \bigr] =
x_0 \phi(d_1) - K e^{-r T} \phi(d_2)
\] avec \(d_1 = \log(S_0 / K) + \frac{(r+\sigma^2/2) T}{\sigma \sqrt{T}}\), \(d_2 = d_1 - \sigma \sqrt{T}\), et \(\phi\) la fonction de répartition d’une loi \(\mathcal{N}(0,1)\).
L’extrapolation de Richardson est une technique simple, très utilisé en analyse numérique, permettant de gagner un ordre de convergence. En effet, en considérant une combinaison linéaire entre un schéma de pas \(\frac{T}{N}\) et un autre de pas \(\frac{T}{2N}\) on peut améliorer l’ordre de convergence en éliminant le premier terme \(\frac{c_1}{N}\) qui apparait dans le développement de l’erreur faible: \[
\mathbb{E} \bigl[ \varphi(x_T) \bigr]
- \mathbb{E} \bigl[ 2 \varphi(X^{2N}_{2N}) - \varphi(X^{N}_{N}) \bigr] = -\frac{c_2}{2 N^2} + \mathcal{O}\bigl( \frac{1}{N^2} \bigr)
\]